Was sind Metadaten?
Metadaten sind Informationen, die die Merkmale anderer Daten enthalten. Konkret auf ein Bild bezogen sind dies die Dateigröße, das Erstellungsdatum, die Anzahl der Pixel und vieles mehr. Neben den Inhaltsdaten, also dem was in einem Bild zu sehen ist, sind die Metadaten die wichtigste Informationsquelle für einen Ermittler in der IT-Forensik. Warum?Ganz einfach! Hier liegen so viele Daten, die einen normalen Nutzer wenig interessieren, die aber sehr viel über sein Verhalten verraten. Gerade bei Smartphones werden in der Regel Standorte in den Metadaten registriert (sog. Geotagging). Das ist schön für uns, wenn wir uns bei Urlaubsfotos per Google Maps später an den genauen Ort „zurückversetzen“ lassen wollen. Das ist aber auch schön für deinen Arbeitgeber, der dieses Bild in deinem Socialmedia-Account gefunden hat. Er fand dabei heraus, dass du dich in der Zeit in der du das Bild vom Strand in Thailand geschossen hast „krank gemeldet“ hast. Anhand der GPS-Daten konnte er dann ganz einfach herausfinden, dass du auf Ko Lon bei Phuket warst. Und als er dich darauf anspricht leugnest du die Sache und sagst, dass das ein Bild war, welches du irgendwo aus dem Internet heruntergeladen hast… Aber schade für dich. In den Metadaten steht in der Regel auch mit welchem Gerät das Foto gemacht wurde!
Wie bekomme ich nun diese Metadaten?…
Für diese Frage gibt es keine eindeutige Antwort, da es sehr viele Wege gibt solche Metadaten zu bekommen. Ich möchte dir nun einen einfachen Ansatz näher erläutern.
…mit dem Tool „IrfanView“
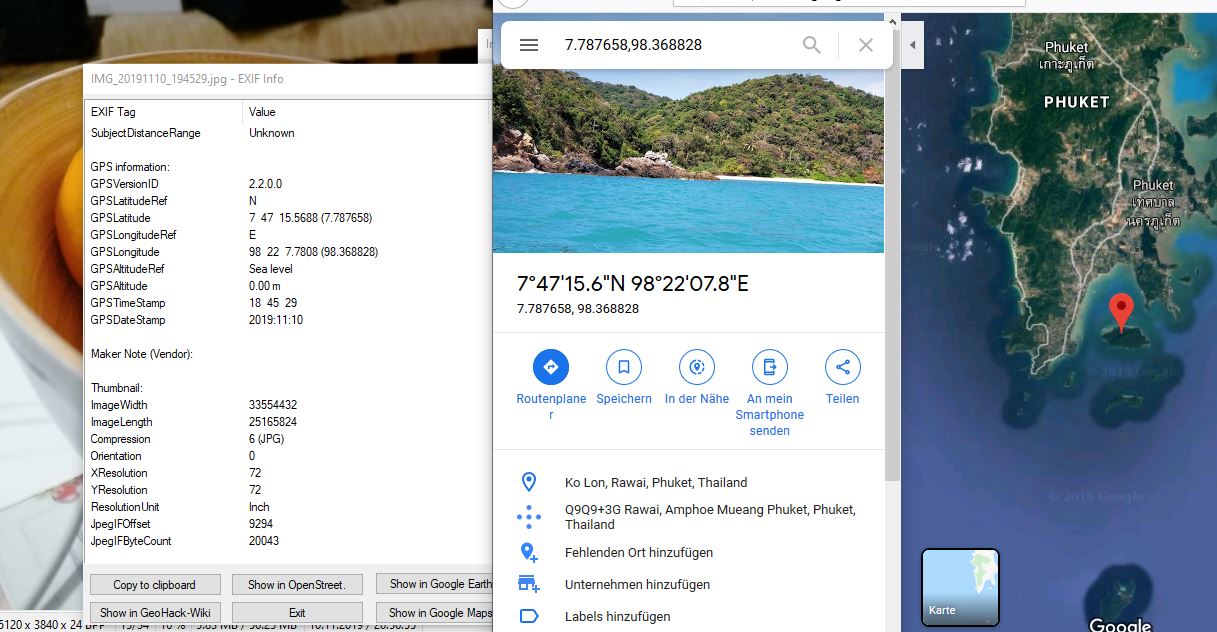
Wer den Foto-Viewer IrfanView auf seinem Computer hat kann die Metadaten sehr einfach auslesen. Über den Menüpunkt „Image“ –> „Information…“ lassen sich einfach Daten anzeigen. Interessant wird es aber erst, wenn man in diesem Popup-Fenster dann auf den Button „EXIF info“ geht. EXIF bedeutet Exchangeable Image Format und ist das Standardformat für die Speicherung von Metadaten bei Bildern. Wie ihr in dem Bild unten sehen könnt, sind wirklich viele Daten dabei sichtbar.
Das Bild habe ich geschossen, als ich den Artikel geschrieben habe (Eigentlich mache ich das Geotagging aus, da ich nicht will, dass Google weiß an welchen Orten ich meine Bilder machte).
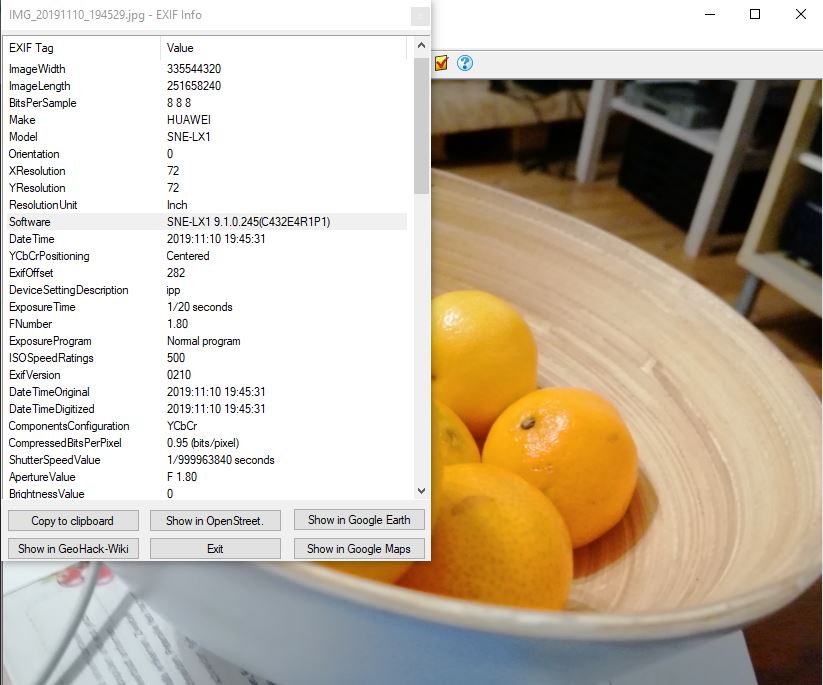
In den EXIF-Daten ist zu sehen, dass ich das Bild mit einem Huawei Handy des Models „SNE-LX1“ geschossen habe. Eine kurze Suche in Google mit dem Begriff zeigt, dass es ein „Huawei Mate 20 lite“ war. Auch die genaue Softwareversion kann ausgelesen werden! Zudem sind Zeitstempel zu sehen, die Aufschluss über die Aufnahmezeit geben.Interessant wird es aber, wenn ich nach unten scrolle. Dort kann man sehen, dass die kompletten GPS-Daten mit in die Metadaten des Bildes geschrieben wurden. Sogar ein GPS-Zeitstempel wird registriert. Interessant..
Metadaten fälschen
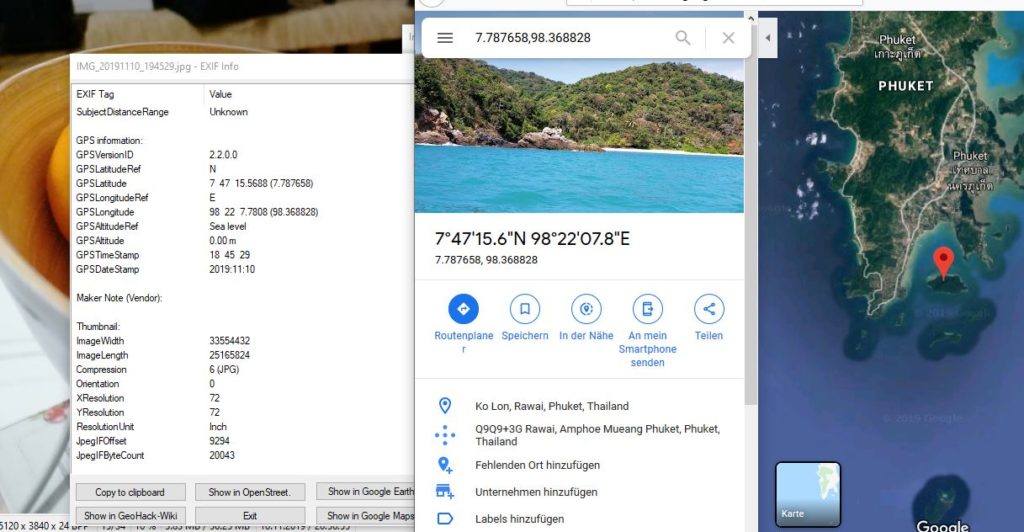
Aber die Daten können trügerisch sein! Die GPS-Tags, die in meinen Metadaten zu sehen sind, sind nicht echt. Ich habe sie gefälscht. Dazu muss ich aber nicht digitale Forensik studieren. Ich musste hierzu lediglich ExifToolGUI herunterladen und konnte bequem die Metadaten bearbeiten. Ich öffnete darin das Bild und gab im Workspace ganz bequem neue Metadaten ein und speicherte sie ab. Das zeigt, dass es in der IT-Forensik sehr wichtig ist die gefundenen Informationen zu hinterfragen und mit anderen Spuren abzugleichen. Sind die Metadaten plausibel zu den anderen Metadaten? Können die Einträge wirklich echt sein?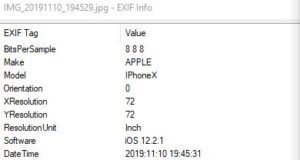
Wie ihr hier im Bild seht, habe ich später mein Huawei zu einem „APPLE IPhoneX“ gemacht und den Eintrag in „Software“ auf „iOS 12.2.1“. Als IT-Forensiker könnte man nun im Internet prüfen, ob ein IPhone X wirklich solche Metadaten hinterlässt oder ob diese anders aussehen müssen. So hätten wir schon einen ersten Hinweis auf Änderung der Metadaten des Bildes. Im weiteren Verlauf müssten daher die Metadaten genauer mit weiteren gefundenen Bildern abgeglichen werden. Dies ist z.B. mit einer Zeitleiste grafisch sehr gut möglich, um die sog. MAC-Times abzugleichen (M = Modification, A = Access, C = Change). Diese spielen in den forensischen Analysen ohnehin bedeutende Rollen und werden in einem anderen Artikel noch erläutert werden.